Network Resilience For Your App With Polly

In this post we will learn about a great library called Polly. With this library we can define policies (you can see where the name came from) on how to deal with failed network requests. This library provides you with easy to use code that let’s you retry, fallback or define other methods to deal with a network request that doesn’t behave as it should.
What Is an App? #
When I talk about apps, I’m not only talking about the instance that is running on your device. When I say “app” I also mean the backend that goes with it, because without it, the app probably doesn’t do much. But while they belong together, there might be a whole world between them, literally. That would the big bad thing called the internet.
In-between, a lot can happen. A user might lose connection while it is waiting for a response or the network might slow down, there’s all kinds of examples that you could come up with. In other words: we, as developers, are expected to deal with this. Each of these scenarios will most likely leave your users with a failed request or timeout. It is a fact that this will happen, the question is: how are we going to deal with it?
The easiest solution would be to put try/catch blocks everywhere and inform the user that something went wrong, maybe even asking the user to retry, but we can go about this a bit smarter. Depending on your target audience, you as the developer are probably more capable of building in a recovery scenario than your users. When a request fails with a HTTP 404 status code, the chances of recovering with a subsequent network request is close to none, while a 500 status code might be a temporary state. With the help of Polly, this is very easy to do!
Assemble! #
At the time of writing the new Avengers movie was just released, so I thought I would create a sample app with the Avengers theme. The app itself isn’t a very exciting app, it shows you some members of the Avengers, you can click through to a few details and from there see in which comics they appear. Or well, some mocked dummy data in case of the comics since I got tired of creating “real” data. Actually, Marvel has a very impressive API to access all kinds of data about the universe they created.
Associated with this app I have built a backend which deliberately triggers a error now and again. Specifically when we go to Captain Marvel and try to get the comics that she appeared in, we will receive a HTTP 500 randomly.
Code for the backend is found in this repository, code for the client app is found here.
Gawk, Polly Wants a Retry #
First, lets have a look at how we would typically do a network call to the backend. The code to retrieve te comics for a specific hero looks like underneath.
With a simple HttpClient we do a request to the backend to retrieve the JSON content and then deserialise it to the .NET objects. Of course, this can be done easier by the use of Refit as shown in this post.
When we start the app as is, and reload the comics for Captain Marvel a few times, it will not take long before we end up with a unhandled exception and crash to the main screen. With a simple try/catch block this can be accounted for, but is it the smartest thing to do? The obvious thing to do is report to the user that our request has failed and kindly ask them to try again. But why bother our users when we can do some first-aid ourselves?
First, we need to install Polly on your shared project through NuGet.
After we did that, let’s see how we are going to transform the code from above to something more robust. If the error occurs, we want to retry our request up to three times. Also, we want to back off our server a little bit with each retry. If we keep firing retry requests quickly after each other the chances aren’t that big that the server is back up yet, even more so: we might start flooding the server with our requests which potentially makes the problem even worse. The enhanced code is shown underneath.
How It Works #
What is happening here is that we wrapped our initial two lines of code in a Polly policy. With the Handle method you can specify which types of exceptions need to be caught. You can even apply some filtering on them, like I do here. In the above code, HttpRequestExceptions are retried, but only when not a HTTP 404. In the next section we specify the conditions of our retry attempt(s). You will notice that in this case, I retry three times. With the sleepDurationProvider we get to specify how long we want to wait between retries.
In this case I take the count of the current retry attempt to a power of two. Now, our retry attempts will have some time between them in a quadratic fashion. Lastly, I specify a handler which is fired whenever a retry occurs. My retry handler is just to show you in the console that a retry happened. You can probably think of some more useful use-cases in a real life scenario.
Finally, in the ExecuteAsync portion, you will find the initial logic that we wanted to execute in the first place. This will be the code that is retried each time. It is probably also good to know that after the three attempts, the exception is still thrown like it normally would.
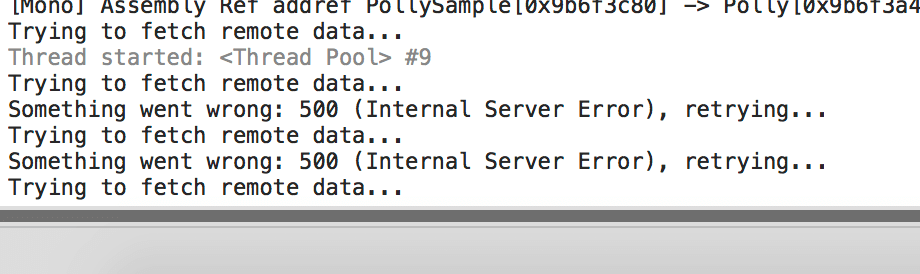
Now, when a request fails and a retry attempt is done, we will see this in our output log.
Summary #
This is just one use of the Polly library. There are a lot more useful things in there. Check out the quick overview table I took from the library project website below. I hope you found this example useful! If you have any questions please reach out to me on Twitter. The code for the sample app used here can be found here: https://github.com/jfversluis/PollySample
A more extensive example combining a few networking libraries can be found here: https://github.com/jfversluis/AirplaneModeProof, pay special attention to the ‘Releases’ section to see it evolve gradually.
| Policy | Premise | Aka | How does the policy mitigate? |
|---|---|---|---|
| Retry (policy family) (quickstart ; deep) | Many faults are transient and may self-correct after a short delay. | “Maybe it’s just a blip” | Allows configuring automatic retries. |
| Circuit-breaker (policy family) (quickstart ; deep) | When a system is seriously struggling, failing fast is better than making users/callers wait. | ||
| Protecting a faulting system from overload can help it recover. | “Stop doing it if it hurts” |
“Give that system a break” | Breaks the circuit (blocks executions) for a period, when faults exceed some pre-configured threshold. | | Timeout (quickstart ; deep) | Beyond a certain wait, a success result is unlikely. | “Don’t wait forever” | Guarantees the caller won’t have to wait beyond the timeout. | | Bulkhead Isolation (quickstart ; deep) | When a process faults, multiple failing calls backing up can easily swamp resource (eg threads/CPU) in a host.
A faulting downstream system can also cause ‘backed-up’ failing calls upstream.
Both risk a faulting process bringing down a wider system. | “One fault shouldn’t sink the whole ship” | Constrains the governed actions to a fixed-size resource pool, isolating their potential to affect others. | | Cache (quickstart ; deep) | Some proportion of requests may be similar. | “You’ve asked that one before” | Provides a response from cache if known.
Stores responses automatically in cache, when first retrieved. | | Fallback (quickstart ; deep) | Things will still fail - plan what you will do when that happens. | “Degrade gracefully” | Defines an alternative value to be returned (or action to be executed) on failure. | | PolicyWrap (quickstart ; deep) | Different faults require different strategies; resilience means using a combination. | “Defence in depth” | Allows any of the above policies to be combined flexibly. |